Batch 的领域语言
Batch 的领域语言
对于任何有经验的批处理架构师来说,批处理的总体概念用于
Spring Batch 应该熟悉且舒适。有“作业”和“步骤”,以及
开发人员提供的处理单元称为ItemReader和ItemWriter.然而
由于 Spring 模式、作、模板、回调和习语,有
以下机会:
-
在遵守明确关注点分离方面有了显着改善。
-
清晰划分的架构层和作为接口提供的服务。
-
简单和默认的实现,允许快速采用和易于使用 开箱即用。
-
显著增强的可扩展性。
下图是批处理参考体系结构的简化版本,其中 已经使用了几十年。它概述了构成 批处理的领域语言。这个架构框架是一个蓝图,它具有 通过过去几代的数十年实施得到证明 平台(COBOL/大型机、C/Unix,以及现在的 Java/任何地方)。JCL 和 COBOL 开发人员 可能与 C、C# 和 Java 开发人员一样熟悉这些概念。Spring Batch 提供层、组件和技术的物理实现 服务常见于健壮、可维护的系统中,用于解决 使用基础设施和扩展创建从简单到复杂的批处理应用程序 以满足非常复杂的加工需求。
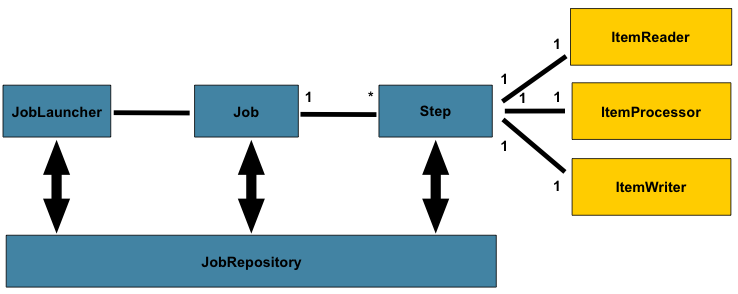
上图突出显示了构成领域语言的关键概念
春季批次。作业有一到多个步骤,每个步骤只有一个ItemReader,
一ItemProcessor,以及一个ItemWriter.需要启动作业(使用JobLauncher),并且需要存储有关当前正在运行的进程的元数据(在JobRepository).
工作
本节介绍与批处理作业概念相关的构造型。一个Job是一个
封装整个批处理的实体。与其他Spring一样
项目,一个Job与 XML 配置文件或基于 Java 的
配置。此配置可称为“作业配置”。然而Job只是整体层次结构的顶部,如下图所示:
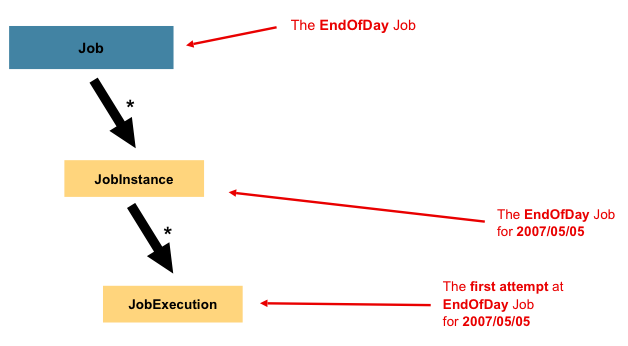
在 Spring Batch 中,一个Job只是一个容器Step实例。它结合了多个
在逻辑上属于流中的步骤,并允许配置属性
全局到所有步骤,例如可重启性。作业配置包含:
-
作业的简单名称。
-
定义和排序
Step实例。 -
作业是否可重新启动。
对于那些使用 Java 配置的用户,Spring Batch 提供了默认的实现
Job 界面以SimpleJob类,它创建了一些标准
功能之上Job.使用基于 java 的配置时,集合
builders 可用于实例化Job,如下所示
例:
@Bean
public Job footballJob() {
return this.jobBuilderFactory.get("footballJob")
.start(playerLoad())
.next(gameLoad())
.next(playerSummarization())
.build();
}
对于那些使用 XML 配置的用户,Spring Batch 提供了Job界面,以SimpleJob类,它创建了一些标准
功能之上Job.但是,批处理命名空间抽象化了
直接实例化它。相反,该<job>元素,如
以下示例:
<job id="footballJob">
<step id="playerload" next="gameLoad"/>
<step id="gameLoad" next="playerSummarization"/>
<step id="playerSummarization"/>
</job>作业实例
一个JobInstance指逻辑作业运行的概念。考虑一个批处理作业
应该在一天结束时运行一次,例如 'EndOfDay'Job从前面
图。有一个“EndOfDay”作业,但每次单独运行的Job必须是
单独跟踪。就这份工作而言,有一个合乎逻辑的JobInstance每天。
例如,有 1 月 1 日运行、1 月 2 日运行,依此类推。如果 1 月 1 日
run 第一次失败,第二天再次运行,它仍然是 1 月 1 日的运行。
(通常,这也与它正在处理的数据相对应,即 1 月
第一次运行处理 1 月 1 日的数据)。因此,每个JobInstance可以有多个
执行 (JobExecution在本章后面会更详细地讨论),并且仅
一JobInstance对应于特定的Job并识别JobParameters能
在给定时间运行。
定义JobInstance对要加载的数据完全没有影响。
这完全取决于ItemReader实现以确定如何加载数据。为
例如,在 EndOfDay 方案中,数据上可能有一个列指示
数据所属的“生效日期”或“计划日期”。所以,1 月 1 日的运行
将仅加载来自第 1 次的数据,而 1 月 2 日的运行将仅使用来自
2. 因为这个决定很可能是一个商业决策,所以它留给ItemReader来决定。但是,使用相同的JobInstance确定是否
“状态”(即ExecutionContext,本章稍后将讨论)
使用以前的执行。使用新的JobInstance意思是“从
开始“,使用现有实例通常意味着”从离开的地方开始”
关闭“。
作业参数
讨论过JobInstance以及它与约伯有何不同,这是自然而然的问题
是:“一个怎么JobInstance与另一个区别?答案是:JobParameters.一个JobParameters对象包含一组用于启动批处理的参数
工作。它们可用于识别,甚至可以在运行过程中用作参考数据,例如
如下图所示:
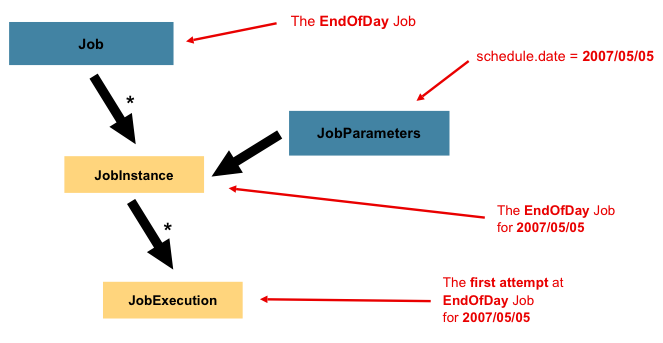
在前面的示例中,有两个实例,一个用于 1 月 1 日,另一个用于 1 月 1 日
对于1月2日,真的只有一个Job,但它有两个JobParameter对象:
一个以 01-01-2017 的作业参数启动,另一个以
参数为 01-02-2017。因此,合约可以定义为:JobInstance = Job+ 识别JobParameters.这允许开发人员有效地控制JobInstance定义,因为它们控制传入的参数。
并非所有作业参数都有助于识别JobInstance.默认情况下,它们会这样做。但是,该框架也允许提交
的Job使用不有助于JobInstance. |
作业执行
一个JobExecution指的是单次尝试运行作业的技术概念。一
执行可能以失败或成功告终,但JobInstance对应于给定的
除非执行成功完成,否则执行不被视为完成。
使用 EndOfDayJob前面描述的示例,请考虑JobInstance为
01-01-2017 第一次运行时失败了。如果再次运行相同的
将作业参数标识为第一次运行(01-01-2017),一个新的JobExecution是
创建。然而,仍然只有一个JobInstance.
一个Job定义作业是什么以及如何执行它,以及JobInstance是一个
纯粹的组织对象将执行分组在一起,主要是为了实现正确的
重启语义。一个JobExecution然而,是什么的主要存储机制
实际发生在运行期间,并且包含更多必须控制的属性
并持久化,如下表所示:
属性 |
定义 |
地位 |
一个 |
开始时间 |
一个 |
结束时间 |
一个 |
退出状态 |
这 |
创建时间 |
一个 |
最后更新 |
一个 |
执行上下文 |
包含需要在 执行。 |
失败异常 |
执行期间遇到的异常列表 |
这些属性很重要,因为它们是持久化的,并且可以完全用于 确定执行的状态。例如,如果 01-01 的 EndOfDay 作业为 在晚上 9:00 执行并在 9:30 失败时,批处理中将进行以下条目 元数据表:
JOB_INST_ID |
JOB_NAME |
1 |
EndOfDayJob |
JOB_EXECUTION_ID |
TYPE_CD |
KEY_NAME |
DATE_VAL |
识别 |
1 |
日期 |
附表。日期 |
2017-01-01 |
true |
JOB_EXEC_ID |
JOB_INST_ID |
START_TIME |
END_TIME |
地位 |
1 |
1 |
2017-01-01 21:00 |
2017-01-01 21:30 |
失败 |
| 为了清楚起见,列名可能已被缩写或删除,并且 格式。 |
现在作业失败了,假设花了整晚的时间才出现问题
确定,因此“批处理窗口”现在已关闭。进一步假设窗口
从晚上 9:00 开始,作业将在 01-01 再次启动,从中断的地方开始,并且
9:30 圆满完成。因为现在是第二天,01-02 的工作肯定是
也运行,紧接着在 9:31 开始并在正常状态下完成
小时时间为 10:30。没有要求JobInstance在之后被踢开
另一个,除非两个作业有可能尝试访问相同的数据,
导致数据库级别锁定问题。这完全取决于调度程序
确定Job应该运行。由于它们是分开的JobInstancesSpring
Batch 不会尝试阻止它们并发运行。(尝试运行
相同JobInstance而另一个已经在运行,则会导致JobExecutionAlreadyRunningException被扔)。现在应该有一个额外的条目
在JobInstance和JobParameters表格和两个额外的条目JobExecution表,如下表所示:
JOB_INST_ID |
JOB_NAME |
1 |
EndOfDayJob |
2 |
EndOfDayJob |
JOB_EXECUTION_ID |
TYPE_CD |
KEY_NAME |
DATE_VAL |
识别 |
1 |
日期 |
附表。日期 |
2017-01-01 00:00:00 |
true |
2 |
日期 |
附表。日期 |
2017-01-01 00:00:00 |
true |
3 |
日期 |
附表。日期 |
2017-01-02 00:00:00 |
true |
JOB_EXEC_ID |
JOB_INST_ID |
START_TIME |
END_TIME |
地位 |
1 |
1 |
2017-01-01 21:00 |
2017-01-01 21:30 |
失败 |
2 |
1 |
2017-01-02 21:00 |
2017-01-02 21:30 |
完成 |
3 |
2 |
2017-01-02 21:31 |
2017-01-02 22:29 |
完成 |
| 为了清楚起见,列名可能已被缩写或删除,并且 格式。 |
步
一个Step是一个域对象,它封装了批处理的独立顺序阶段
工作。因此,每个作业都完全由一个或多个步骤组成。一个Step包含
定义和控制实际批处理所需的所有信息。这
必然是一个模糊的描述,因为任何给定的内容Step位于
开发人员的自由裁量权编写Job.一个Step可以像
开发商的愿望。一个简单的Step可能会将数据从文件加载到数据库中,
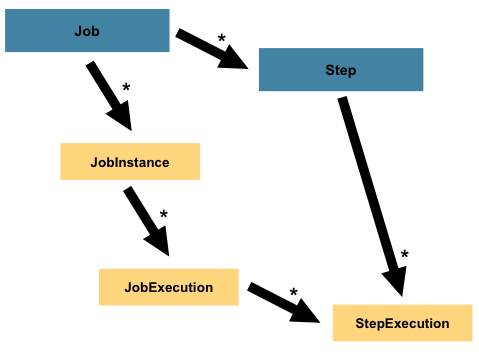
需要很少或不需要代码(取决于所使用的实现)。更复杂的Step可能具有作为处理的一部分应用的复杂业务规则。 如 使用Job一个Step有一个个体StepExecution与独特的JobExecution,如下图所示:
步骤执行
一个StepExecution表示执行Step.一个新的StepExecution每次创建Step运行,类似于JobExecution.但是,如果某个步骤失败
执行,因为它之前的步骤失败,因此不会为它保留任何执行。一个StepExecution仅当其Step实际上已经开始了。
Step执行由StepExecution类。每次执行
包含对其相应步骤的引用,并且JobExecution和交易相关
数据,例如提交和回滚计数以及开始和结束时间。此外,每个步骤
执行包含一个ExecutionContext,其中包含开发人员需要的任何数据
在批处理运行中持久存在,例如所需的统计信息或状态信息
重新启动。下表列出了StepExecution:
属性 |
定义 |
地位 |
一个 |
开始时间 |
一个 |
结束时间 |
一个 |
退出状态 |
这 |
执行上下文 |
包含需要在 执行。 |
读取计数 |
已成功读取的项目数。 |
写计数 |
已成功写入的项数。 |
提交计数 |
已为此执行提交的事务数。 |
回滚计数 |
业务事务由 |
readSkipCount |
次数 |
processSkipCount |
次数 |
过滤器计数 |
已通过 |
写入跳过计数 |
次数 |
执行上下文
一ExecutionContext表示持久化的键/值对的集合,并且
由框架控制,以便为开发人员提供一个存储持久性
作用域限定为StepExecutionobject 或JobExecution对象。对于那些
熟悉 Quartz,它与 JobDataMap 非常相似。最好的用法示例是
促进重启。以平面文件输入为例,在处理单个
行,框架会定期保留ExecutionContext在提交点。行为
因此允许ItemReader存储其状态,以防在运行过程中发生致命错误
或者即使停电。所需要做的就是输入当前的行数
读取上下文,如以下示例所示,框架将执行
休息:
executionContext.putLong(getKey(LINES_READ_COUNT), reader.getPosition());
使用Job以刻板印象部分为例,假设那里
是一个步骤,“loadData”,将文件加载到数据库中。在第一次失败运行后,
元数据表将如以下示例所示:
JOB_INST_ID |
JOB_NAME |
1 |
EndOfDayJob |
JOB_INST_ID |
TYPE_CD |
KEY_NAME |
DATE_VAL |
1 |
日期 |
附表。日期 |
2017-01-01 |
JOB_EXEC_ID |
JOB_INST_ID |
START_TIME |
END_TIME |
地位 |
1 |
1 |
2017-01-01 21:00 |
2017-01-01 21:30 |
失败 |
STEP_EXEC_ID |
JOB_EXEC_ID |
STEP_NAME |
START_TIME |
END_TIME |
地位 |
1 |
1 |
loadData |
2017-01-01 21:00 |
2017-01-01 21:30 |
失败 |
STEP_EXEC_ID |
SHORT_CONTEXT |
1 |
{件数=40321} |
在前面的案例中,Step运行了 30 分钟并处理了 40,321 个“片段”,其中在这种情况下,将表示文件中的行。此值在每个之前更新由框架提交,并且可以包含与ExecutionContext. 在提交之前收到通知需要各种StepListener实现(或ItemStream),这将更详细地讨论本指南后面。与前面的示例一样,假设Job是 第二天重新启动。重新启动时,来自ExecutionContext之 最后一次运行是从数据库中重构的。当ItemReader打开时,它可以检查它在上下文中是否有任何存储状态,并从那里初始化自身,如以下示例所示:
if (executionContext.containsKey(getKey(LINES_READ_COUNT))) {
log.debug("Initializing for restart. Restart data is: " + executionContext);
long lineCount = executionContext.getLong(getKey(LINES_READ_COUNT));
LineReader reader = getReader();
Object record = "";
while (reader.getPosition() < lineCount && record != null) {
record = readLine();
}
}
在这种情况下,在上述代码运行后,当前行为 40,322,允许Step从上次中断的地方重新开始。 这ExecutionContext也可用于需要保留有关运行本身的统计数据。例如,如果一个平面文件包含跨多行存在的处理订单,则可能需要存储已处理的订单数量(这与读取的行数有很大不同),以便可以在Step总数正文中处理的订单数。框架为开发人员处理存储此内容,在以便正确地将其范围与个人JobInstance.这可能非常困难
知道现有的ExecutionContext应该使用与否。例如,使用
上面的“EndOfDay”示例,当 01-01 运行第二次再次开始时,
框架认识到它是相同的JobInstance和个人Step基础
将ExecutionContext,并将其交给数据库(作为StepExecution) 设置为Step本身。相反,对于 01-02 运行,框架
认识到它是一个不同的实例,因此必须将空上下文交给Step.该框架为以下项目做出了许多此类决定
developer,以确保在正确的时间向他们提供状态。这也很重要
请注意,恰好一个ExecutionContext存在StepExecution在任何给定时间。
的客户ExecutionContext应该小心,因为这会创建一个共享的
keyspace。因此,在输入值时应小心,以确保没有数据
覆盖。但是,Step在上下文中绝对不存储任何数据,因此没有
对框架产生不利影响的方式。
同样重要的是要注意,至少有一个ExecutionContext每JobExecution每个人一个StepExecution.例如,考虑以下内容
代码片段:
ExecutionContext ecStep = stepExecution.getExecutionContext();
ExecutionContext ecJob = jobExecution.getExecutionContext();
//ecStep does not equal ecJob
正如评论中所指出的,ecStep不等于ecJob.他们是两个不同的ExecutionContexts.作用域限定为Step保存在Step,而作用域为 Job 的 Job 保存在每个Step执行。
在ExecutionContext,则所有非瞬态条目必须是Serializable.
执行上下文的正确序列化支持步骤和作业的重启功能。
如果您使用本机不可序列化的键或值,则需要
采用量身定制的序列化方法。无法序列化执行上下文
可能会危及状态持久化过程,使失败的作业无法正确恢复。 |
作业存储库
JobRepository是上述所有刻板印象的持久性机制。
它为JobLauncher,Job和Step实现。当Job首次启动时,一个JobExecution从存储库获取,并且在
执行过程,StepExecution和JobExecution实现被持久化
通过将它们传递到存储库。
Spring Batch XML 命名空间支持配置JobRepository实例
使用<job-repository>标记,如以下示例所示:
<job-repository id="jobRepository"/>使用 Java 配置时,@EnableBatchProcessing注释提供了一个JobRepository作为开箱即用自动配置的组件之一。
作业Starters
JobLauncher表示用于启动Job使用一组给定的JobParameters,如以下示例所示:
public interface JobLauncher {
public JobExecution run(Job job, JobParameters jobParameters)
throws JobExecutionAlreadyRunningException, JobRestartException,
JobInstanceAlreadyCompleteException, JobParametersInvalidException;
}
预期实现将获得有效的JobExecution从JobRepository并执行Job.
项目阅读器
ItemReader是一个抽象,表示对输入的检索Step一
一次项目。当ItemReader已经用尽了它能提供的物品,它
通过返回null.有关ItemReader接口及其
可以在 Readers And Writers 中找到各种实现。
项目写入器
ItemWriter是一个抽象,表示Step、一个批次或块
一次的项目。通常,一个ItemWriter不知道它应该输入的
receive next,并且仅知道在其当前调用中传递的项。更多
关于ItemWriter接口及其各种实现可以在 Readers And Writers 中找到。
物品处理器
ItemProcessor是表示项目的业务处理的抽象。
虽然ItemReader读取一项,并且ItemWriter写下它们,ItemProcessor提供一个接入点来转换或应用其他业务处理。
如果在处理项目时,确定该项目无效,则返回null表示不应写出该项目。有关ItemProcessor界面可以在读写器中找到。
批处理命名空间
前面列出的许多领域概念需要在 Spring 中配置ApplicationContext.虽然上面有接口的实现,但可以
在标准 bean 定义中使用,提供了一个命名空间以方便
配置,如以下示例所示:
<beans:beans xmlns="http://www.springframework.org/schema/batch"
xmlns:beans="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="
http://www.springframework.org/schema/beans
https://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/batch
https://www.springframework.org/schema/batch/spring-batch.xsd">
<job id="ioSampleJob">
<step id="step1">
<tasklet>
<chunk reader="itemReader" writer="itemWriter" commit-interval="2"/>
</tasklet>
</step>
</job>
</beans:beans>