Advanced Metadata Usage
So far, both the JobLauncher and JobRepository interfaces have been
discussed. Together, they represent the simple launching of a job and basic
CRUD operations of batch domain objects:
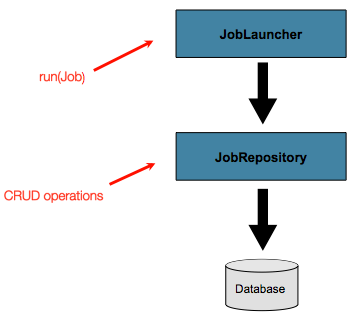
A JobLauncher uses the
JobRepository to create new
JobExecution objects and run them.
Job and Step implementations
later use the same JobRepository for basic updates
of the same executions during the running of a Job.
The basic operations suffice for simple scenarios. However, in a large batch
environment with hundreds of batch jobs and complex scheduling
requirements, more advanced access to the metadata is required:
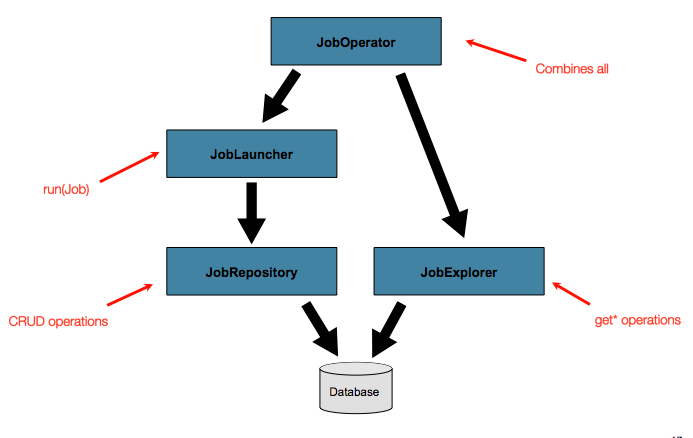
The JobExplorer and
JobOperator interfaces, which are discussed
in the coming sections, add additional functionality for querying and controlling the metadata.
Querying the Repository
The most basic need before any advanced features is the ability to
query the repository for existing executions. This functionality is
provided by the JobExplorer interface:
public interface JobExplorer {
List<JobInstance> getJobInstances(String jobName, int start, int count);
JobExecution getJobExecution(Long executionId);
StepExecution getStepExecution(Long jobExecutionId, Long stepExecutionId);
JobInstance getJobInstance(Long instanceId);
List<JobExecution> getJobExecutions(JobInstance jobInstance);
Set<JobExecution> findRunningJobExecutions(String jobName);
}As is evident from its method signatures, JobExplorer is a read-only version of
the JobRepository, and, like the JobRepository, it can be easily configured by using a
factory bean.
-
Java
-
XML
The following example shows how to configure a JobExplorer in Java:
...
// This would reside in your DefaultBatchConfiguration extension
@Bean
public JobExplorer jobExplorer() throws Exception {
JobExplorerFactoryBean factoryBean = new JobExplorerFactoryBean();
factoryBean.setDataSource(this.dataSource);
return factoryBean.getObject();
}
...The following example shows how to configure a JobExplorer in XML:
<bean id="jobExplorer" class="org.spr...JobExplorerFactoryBean"
p:dataSource-ref="dataSource" />Earlier in this chapter, we noted that you can modify the table prefix
of the JobRepository to allow for different versions or schemas. Because
the JobExplorer works with the same tables, it also needs the ability to set a prefix.
-
Java
-
XML
The following example shows how to set the table prefix for a JobExplorer in Java:
...
// This would reside in your DefaultBatchConfiguration extension
@Bean
public JobExplorer jobExplorer() throws Exception {
JobExplorerFactoryBean factoryBean = new JobExplorerFactoryBean();
factoryBean.setDataSource(this.dataSource);
factoryBean.setTablePrefix("SYSTEM.");
return factoryBean.getObject();
}
...The following example shows how to set the table prefix for a JobExplorer in XML:
<bean id="jobExplorer" class="org.spr...JobExplorerFactoryBean"
p:tablePrefix="SYSTEM."/>JobRegistry
A JobRegistry (and its parent interface, JobLocator) is not mandatory, but it can be
useful if you want to keep track of which jobs are available in the context. It is also
useful for collecting jobs centrally in an application context when they have been created
elsewhere (for example, in child contexts). You can also use custom JobRegistry implementations
to manipulate the names and other properties of the jobs that are registered.
There is only one implementation provided by the framework and this is based on a simple
map from job name to job instance.
-
Java
-
XML
When using @EnableBatchProcessing, a JobRegistry is provided for you.
The following example shows how to configure your own JobRegistry:
...
// This is already provided via the @EnableBatchProcessing but can be customized via
// overriding the bean in the DefaultBatchConfiguration
@Override
@Bean
public JobRegistry jobRegistry() throws Exception {
return new MapJobRegistry();
}
...The following example shows how to include a JobRegistry for a job defined in XML:
<bean id="jobRegistry" class="org.springframework.batch.core.configuration.support.MapJobRegistry" />You can populate a JobRegistry in one of the following ways: by using
a bean post processor, or by using a smart initializing singleton or by using
a registrar lifecycle component. The coming sections describe these mechanisms.
JobRegistryBeanPostProcessor
This is a bean post-processor that can register all jobs as they are created.
-
Java
-
XML
The following example shows how to include the JobRegistryBeanPostProcessor for a job
defined in Java:
@Bean
public JobRegistryBeanPostProcessor jobRegistryBeanPostProcessor(JobRegistry jobRegistry) {
JobRegistryBeanPostProcessor postProcessor = new JobRegistryBeanPostProcessor();
postProcessor.setJobRegistry(jobRegistry);
return postProcessor;
}The following example shows how to include the JobRegistryBeanPostProcessor for a job
defined in XML:
<bean id="jobRegistryBeanPostProcessor" class="org.spr...JobRegistryBeanPostProcessor">
<property name="jobRegistry" ref="jobRegistry"/>
</bean>Although it is not strictly necessary, the post-processor in the
example has been given an id so that it can be included in child
contexts (for example, as a parent bean definition) and cause all jobs created
there to also be registered automatically.
|
Deprecation
As of version 5.2, the |
JobRegistrySmartInitializingSingleton
This is a SmartInitializingSingleton that registers all singleton jobs within the job registry.
-
Java
-
XML
The following example shows how to define a JobRegistrySmartInitializingSingleton in Java:
@Bean
public JobRegistrySmartInitializingSingleton jobRegistrySmartInitializingSingleton(JobRegistry jobRegistry) {
return new JobRegistrySmartInitializingSingleton(jobRegistry);
}The following example shows how to define a JobRegistrySmartInitializingSingleton in XML:
<bean class="org.springframework.batch.core.configuration.support.JobRegistrySmartInitializingSingleton">
<property name="jobRegistry" ref="jobRegistry" />
</bean>AutomaticJobRegistrar
This is a lifecycle component that creates child contexts and registers jobs from those
contexts as they are created. One advantage of doing this is that, while the job names in
the child contexts still have to be globally unique in the registry, their dependencies
can have “natural” names. So, for example, you can create a set of XML configuration files
that each have only one Job but that all have different definitions of an ItemReader with the
same bean name, such as reader. If all those files were imported into the same context,
the reader definitions would clash and override one another, but, with the automatic
registrar, this is avoided. This makes it easier to integrate jobs that have been contributed from
separate modules of an application.
-
Java
-
XML
The following example shows how to include the AutomaticJobRegistrar for a job defined
in Java:
@Bean
public AutomaticJobRegistrar registrar() {
AutomaticJobRegistrar registrar = new AutomaticJobRegistrar();
registrar.setJobLoader(jobLoader());
registrar.setApplicationContextFactories(applicationContextFactories());
registrar.afterPropertiesSet();
return registrar;
}The following example shows how to include the AutomaticJobRegistrar for a job defined
in XML:
<bean class="org.spr...AutomaticJobRegistrar">
<property name="applicationContextFactories">
<bean class="org.spr...ClasspathXmlApplicationContextsFactoryBean">
<property name="resources" value="classpath*:/config/job*.xml" />
</bean>
</property>
<property name="jobLoader">
<bean class="org.spr...DefaultJobLoader">
<property name="jobRegistry" ref="jobRegistry" />
</bean>
</property>
</bean>The registrar has two mandatory properties: an array of
ApplicationContextFactory (created from a
convenient factory bean in the preceding example) and a
JobLoader. The JobLoader
is responsible for managing the lifecycle of the child contexts and
registering jobs in the JobRegistry.
The ApplicationContextFactory is
responsible for creating the child context. The most common usage
is (as in the preceding example) to use a
ClassPathXmlApplicationContextFactory. One of
the features of this factory is that, by default, it copies some of the
configuration down from the parent context to the child. So, for
instance, you need not redefine the
PropertyPlaceholderConfigurer or AOP
configuration in the child, provided it should be the same as the
parent.
You can use AutomaticJobRegistrar in
conjunction with a JobRegistryBeanPostProcessor
(as long as you also use DefaultJobLoader).
For instance, this might be desirable if there are jobs
defined in the main parent context as well as in the child
locations.
JobOperator
As previously discussed, the JobRepository
provides CRUD operations on the meta-data, and the
JobExplorer provides read-only operations on the
metadata. However, those operations are most useful when used together
to perform common monitoring tasks such as stopping, restarting, or
summarizing a Job, as is commonly done by batch operators. Spring Batch
provides these types of operations in the
JobOperator interface:
public interface JobOperator {
List<Long> getExecutions(long instanceId) throws NoSuchJobInstanceException;
List<Long> getJobInstances(String jobName, int start, int count)
throws NoSuchJobException;
Set<Long> getRunningExecutions(String jobName) throws NoSuchJobException;
String getParameters(long executionId) throws NoSuchJobExecutionException;
Long start(String jobName, String parameters)
throws NoSuchJobException, JobInstanceAlreadyExistsException;
Long restart(long executionId)
throws JobInstanceAlreadyCompleteException, NoSuchJobExecutionException,
NoSuchJobException, JobRestartException;
Long startNextInstance(String jobName)
throws NoSuchJobException, JobParametersNotFoundException, JobRestartException,
JobExecutionAlreadyRunningException, JobInstanceAlreadyCompleteException;
boolean stop(long executionId)
throws NoSuchJobExecutionException, JobExecutionNotRunningException;
String getSummary(long executionId) throws NoSuchJobExecutionException;
Map<Long, String> getStepExecutionSummaries(long executionId)
throws NoSuchJobExecutionException;
Set<String> getJobNames();
}The preceding operations represent methods from many different interfaces, such as
JobLauncher, JobRepository, JobExplorer, and JobRegistry. For this reason, the
provided implementation of JobOperator (SimpleJobOperator) has many dependencies.
-
Java
-
XML
The following example shows a typical bean definition for SimpleJobOperator in Java:
/**
* All injected dependencies for this bean are provided by the @EnableBatchProcessing
* infrastructure out of the box.
*/
@Bean
public SimpleJobOperator jobOperator(JobExplorer jobExplorer,
JobRepository jobRepository,
JobRegistry jobRegistry,
JobLauncher jobLauncher) {
SimpleJobOperator jobOperator = new SimpleJobOperator();
jobOperator.setJobExplorer(jobExplorer);
jobOperator.setJobRepository(jobRepository);
jobOperator.setJobRegistry(jobRegistry);
jobOperator.setJobLauncher(jobLauncher);
return jobOperator;
}The following example shows a typical bean definition for SimpleJobOperator in XML:
<bean id="jobOperator" class="org.spr...SimpleJobOperator">
<property name="jobExplorer">
<bean class="org.spr...JobExplorerFactoryBean">
<property name="dataSource" ref="dataSource" />
</bean>
</property>
<property name="jobRepository" ref="jobRepository" />
<property name="jobRegistry" ref="jobRegistry" />
<property name="jobLauncher" ref="jobLauncher" />
</bean>As of version 5.0, the @EnableBatchProcessing annotation automatically registers a job operator bean
in the application context.
| If you set the table prefix on the job repository, do not forget to set it on the job explorer as well. |
JobParametersIncrementer
Most of the methods on JobOperator are
self-explanatory, and you can find more detailed explanations in the
Javadoc of the interface. However, the
startNextInstance method is worth noting. This
method always starts a new instance of a Job.
This can be extremely useful if there are serious issues in a
JobExecution and the Job
needs to be started over again from the beginning. Unlike
JobLauncher (which requires a new
JobParameters object that triggers a new
JobInstance), if the parameters are different from
any previous set of parameters, the
startNextInstance method uses the
JobParametersIncrementer tied to the
Job to force the Job to a
new instance:
public interface JobParametersIncrementer {
JobParameters getNext(JobParameters parameters);
}The contract of JobParametersIncrementer is
that, given a JobParameters
object, it returns the “next” JobParameters
object by incrementing any necessary values it may contain. This
strategy is useful because the framework has no way of knowing what
changes to the JobParameters make it the “next”
instance. For example, if the only value in
JobParameters is a date and the next instance
should be created, should that value be incremented by one day or one
week (if the job is weekly, for instance)? The same can be said for any
numerical values that help to identify the Job,
as the following example shows:
public class SampleIncrementer implements JobParametersIncrementer {
public JobParameters getNext(JobParameters parameters) {
if (parameters==null || parameters.isEmpty()) {
return new JobParametersBuilder().addLong("run.id", 1L).toJobParameters();
}
long id = parameters.getLong("run.id",1L) + 1;
return new JobParametersBuilder().addLong("run.id", id).toJobParameters();
}
}In this example, the value with a key of run.id is used to
discriminate between JobInstances. If the
JobParameters passed in is null, it can be
assumed that the Job has never been run before
and, thus, its initial state can be returned. However, if not, the old
value is obtained, incremented by one, and returned.
-
Java
-
XML
For jobs defined in Java, you can associate an incrementer with a Job through the
incrementer method provided in the builders, as follows:
@Bean
public Job footballJob(JobRepository jobRepository) {
return new JobBuilder("footballJob", jobRepository)
.incrementer(sampleIncrementer())
...
.build();
}For jobs defined in XML, you can associate an incrementer with a Job through the
incrementer attribute in the namespace, as follows:
<job id="footballJob" incrementer="sampleIncrementer">
...
</job>Stopping a Job
One of the most common use cases of
JobOperator is gracefully stopping a
Job:
Set<Long> executions = jobOperator.getRunningExecutions("sampleJob");
jobOperator.stop(executions.iterator().next());The shutdown is not immediate, since there is no way to force
immediate shutdown, especially if the execution is currently in
developer code that the framework has no control over, such as a
business service. However, as soon as control is returned back to the
framework, it sets the status of the current
StepExecution to
BatchStatus.STOPPED, saves it, and does the same
for the JobExecution before finishing.
Aborting a Job
A job execution that is FAILED can be
restarted (if the Job is restartable). A job execution whose status is
ABANDONED cannot be restarted by the framework.
The ABANDONED status is also used in step
executions to mark them as skippable in a restarted job execution. If a
job is running and encounters a step that has been marked
ABANDONED in the previous failed job execution, it
moves on to the next step (as determined by the job flow definition
and the step execution exit status).
If the process died (kill -9 or server
failure), the job is, of course, not running, but the JobRepository has
no way of knowing because no one told it before the process died. You
have to tell it manually that you know that the execution either failed
or should be considered aborted (change its status to
FAILED or ABANDONED). This is
a business decision, and there is no way to automate it. Change the
status to FAILED only if it is restartable and you know that the restart data is valid.