|
对于最新稳定版本,请使用 Spring Batch 文档 6.0.3! |
批处理的领域语言
对于任何有经验的批处理架构师来说,Spring Batch 中使用的批处理整体概念应该是熟悉且舒适的。这里有
-
显著改进了对清晰关注点分离的遵循。
-
清晰划分的架构层以及以接口形式提供的服务。
-
简单且默认的实现,支持开箱即用的快速采用和便捷使用。
-
显著增强了可扩展性。
下图是批处理参考架构的简化版本,该架构已沿用数十年。它概述了构成批处理领域语言的各个组件。此架构框架是一个蓝图,已在过去几代平台(大型机上的 COBOL、Unix 上的 C,以及如今无处不在的 Java)上经过数十年的实施验证。JCL 和 COBOL 开发者很可能与 C、C# 和 Java 开发者一样熟悉这些概念。Spring Batch 提供了层、组件和技术服务的物理实现,这些内容常见于用于构建从简单到复杂批处理应用的健壮且可维护的系统中,并具备相应的基础设施和扩展能力,以满足非常复杂的处理需求。
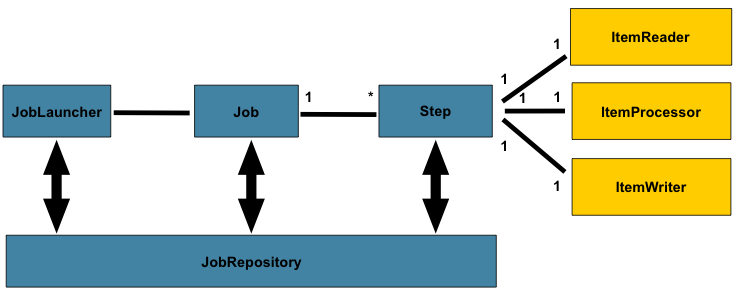
上述图表突出了构成 Spring Batch 领域语言的关键概念。一个Job包含一到多个步骤,每个步骤恰好包含一个ItemReader、一个ItemProcessor和一个ItemWriter。作业需要通过JobLauncher启动,并且当前运行进程的元数据需要存储在JobRepository中。
职位
本节描述了与批处理作业概念相关的构造型。Job 是一个封装了整个批处理过程的实体。与其他 Spring 项目一样,Job 可以通过 XML 配置文件或基于 Java 的配置进行装配。此配置可称为“作业配置”。然而,Job 仅是整体层次结构的顶层,如下图所示:
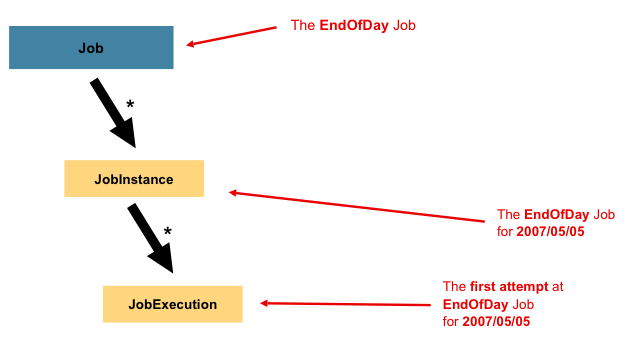
在 Spring Batch 中,Job 仅仅是 Step 实例的容器。它将逻辑上属于同一流程的多个步骤组合在一起,并允许配置对所有步骤全局有效的属性(例如可重启性)。作业配置包含:
-
职位名称。
-
Step实例的定义和排序。 -
作业是否可重启。
-
Java
-
XML
对于使用 Java 配置的用户,Spring Batch 以 SimpleJob 类的形式提供了 Job 接口的默认实现,该实现在 Job 之上创建了一些标准功能。当使用基于 Java 的配置时,提供了一组构建器用于实例化 Job,如下例所示:
@Bean
public Job footballJob(JobRepository jobRepository) {
return new JobBuilder("footballJob", jobRepository)
.start(playerLoad())
.next(gameLoad())
.next(playerSummarization())
.build();
}对于使用 XML 配置的用户,Spring Batch 以 SimpleJob 类的形式提供了 Job 接口的默认实现,该类在 Job 之上创建了一些标准功能。然而,批处理命名空间抽象了直接实例化它的需求。相反,您可以使用 <job> 元素,如下例所示:
<job id="footballJob">
<step id="playerload" next="gameLoad"/>
<step id="gameLoad" next="playerSummarization"/>
<step id="playerSummarization"/>
</job>作业实例
JobInstance 指的是逻辑作业运行的概念。考虑一个应在每天结束时运行一次的批处理作业,例如前图所示的 EndOfDay Job。这里只有一个 EndOfDay 作业,但 Job 的每次独立运行都必须单独跟踪。就本作业而言,每天有一个逻辑 JobInstance。例如,有 1 月 1 日的运行、1 月 2 日的运行,依此类推。如果 1 月 1 日的运行首次失败并在次日重新运行,它仍然属于 1 月 1 日的运行。(通常,这也与其处理的数据相对应,即 1 月 1 日的运行处理的是 1 月 1 日的数据)。因此,每个 JobInstance 可以有多次执行(JobExecution 将在本章稍后部分详细讨论),而在给定时间内只能有一个 JobInstance(对应于特定的 Job 和标识符 JobParameters)在运行。
JobInstance 的定义对要加载的数据没有任何影响。
数据如何加载完全由 ItemReader 的实现来决定。例如,在 EndOfDay 场景中,数据中可能包含一列,用于指示该数据所属的 effective date 或 schedule date。因此,1 月 1 日的运行只会加载 1 日的數據,而 1 月 2 日的运行则只使用 2 日的數據。由于这种判定通常属于业务决策,因此交由 ItemReader 来决定。然而,使用相同的 JobInstance 将决定是否沿用之前执行时的“状态”(即 ExecutionContext,本章稍后将讨论)。使用新的 JobInstance 意味着“从头开始”,而使用现有实例通常意味着“从上次停止的地方继续”。
作业参数
在讨论了JobInstance及其与Job的区别之后,自然要问的问题是:“如何区分一个JobInstance与另一个JobInstance?”答案是:JobParameters。JobParameters对象包含一组用于启动批处理作业的参数。它们可用于身份识别,甚至在运行期间作为参考数据使用,如下图所示:
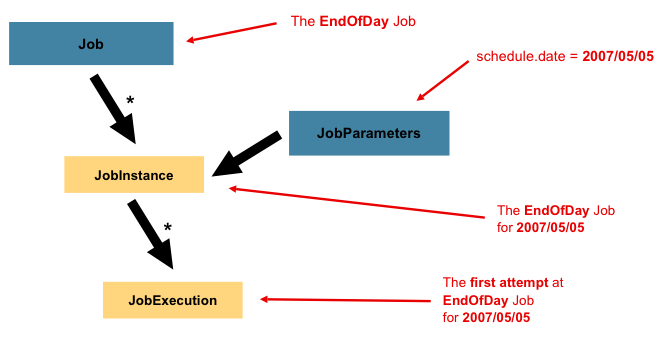
在前面的示例中,虽然有两个实例(一个对应 1 月 1 日,另一个对应 1 月 2 日),但实际上只有一个 Job,但它拥有两个 JobParameter 对象:一个是以作业参数 01-01-2017 启动的,另一个是以参数 01-02-2017 启动的。因此,该契约可定义为:JobInstance = Job + 识别用的 JobParameters。这使得开发人员能够有效控制 JobInstance 的定义方式,因为他们可以控制传入的参数。
并非所有作业参数都需要有助于识别一个JobInstance。默认情况下,它们会这样做。然而,该框架还允许提交带有不参与JobInstance身份标识的参数的Job。 |
作业执行
JobExecution 指的是尝试运行一个作业(Job)的单次技术概念。一次执行可能会以失败或成功告终,但对应于给定执行的 JobInstance 只有在执行成功完成后才被视为完成。以前述的 EndOfDay Job 为例,考虑一个针对 2017 年 1 月 1 日的 JobInstance,它在首次运行时失败了。如果使用与第一次运行相同的作业参数(2017 年 1 月 1 日)再次运行,则会创建一个新的 JobExecution。然而,仍然只有一个 JobInstance。
Job 定义了作业是什么以及如何执行,而JobInstance是一个纯粹的组织性对象,用于将多次执行分组在一起,主要目的是启用正确的重启语义。然而,JobExecution是存储运行期间实际发生情况的主要机制,并包含许多必须被控制和持久化的属性,如下表所示:
属性 |
定义 |
|
一个 |
|
一个 |
|
一个 |
|
|
|
一个 |
|
一个 |
|
包含需要在执行之间持久化的任何用户数据的“属性包”。 |
|
在 |
这些属性非常重要,因为它们会被持久化,并可用于完全确定执行的状态。例如,如果 01-01 的 EndOfDay 号作业在晚上 9:00 执行并在 9:30 失败,则会在批处理元数据表中创建以下条目:
JOB_INST_ID |
JOB_NAME |
1 |
每日终结任务 |
JOB_EXECUTION_ID |
TYPE_CD |
KEY_NAME |
DATE_VAL |
识别中 |
1 |
日期 |
schedule.Date |
2017-01-01 |
true |
JOB_EXEC_ID |
JOB_INST_ID |
START_TIME |
END_TIME |
状态 |
1 |
1 |
2017-01-01 21:00 |
2017-01-01 21:30 |
失败 |
| 为了清晰和格式美观,列名可能已被缩写或移除。 |
既然任务已经失败,假设花费了整整一夜才确定问题所在,因此“批处理窗口”现已关闭。进一步假设窗口从晚上 9:00 开始,该作业将再次为 01-01 启动,从中断处继续执行,并于 9:30 成功完成。因为现在已经是第二天,01-02 任务也必须运行,它随后在 9:31 启动,并在正常的 1 小时内于 10:30 完成。并没有要求一个 JobInstance 必须在另一个之后启动,除非这两个任务有可能尝试访问相同的数据,从而在数据库层面引发锁的问题。完全由调度器决定何时运行 Job。由于它们是独立的 JobInstances,Spring Batch 不会尝试阻止它们并发运行。(尝试在另一个实例已经运行时运行相同的JobInstance,将导致抛出JobExecutionAlreadyRunningException)。现在应该在 JobInstance 和 JobParameters 表中各多出一条记录,在 JobExecution 表中多出两条记录,如下表所示:
JOB_INST_ID |
JOB_NAME |
1 |
每日终结任务 |
2 |
每日终结任务 |
JOB_EXECUTION_ID |
TYPE_CD |
KEY_NAME |
DATE_VAL |
识别中 |
1 |
日期 |
schedule.Date |
2017-01-01 00:00:00 |
true |
2 |
日期 |
schedule.Date |
2017-01-01 00:00:00 |
true |
3 |
日期 |
schedule.Date |
2017-01-02 00:00:00 |
true |
JOB_EXEC_ID |
JOB_INST_ID |
START_TIME |
END_TIME |
状态 |
1 |
1 |
2017-01-01 21:00 |
2017-01-01 21:30 |
失败 |
2 |
1 |
2017-01-02 21:00 |
2017-01-02 21:30 |
已完成 |
3 |
2 |
2017-01-02 21:31 |
2017-01-02 22:29 |
已完成 |
| 为了清晰和格式美观,列名可能已被缩写或移除。 |
步骤
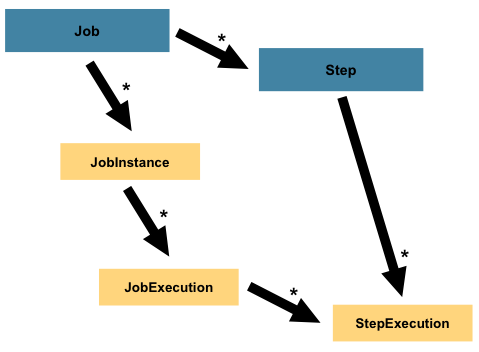
Step 是一个领域对象,用于封装批处理作业中独立且顺序执行的阶段。因此,每个Job完全由一个或多个步骤组成。Step包含定义和控制实际批处理所需的所有信息。由于任何给定Step的内容完全由编写Job的开发人员自行决定,因此上述描述必然较为笼统。Step的复杂程度可由开发人员灵活设定:一个简单的Step可能仅需将数据从文件加载到数据库,几乎无需编写代码(具体取决于所采用的实现方式);而更复杂的Step则可能在处理过程中应用复杂的业务规则。与Job类似,Step也拥有独立的StepExecution,该标识符对应唯一的JobExecution,如下图所示:
步骤执行
一个 StepExecution 代表执行一次 Step 的尝试。每次运行 Step 时都会创建一个新的 StepExecution,类似于 JobExecution。但是,如果某个步骤由于其前一步骤失败而未能执行,则不会为其持久化任何执行记录。只有当其 Step 实际启动时,才会创建 StepExecution。
Step 次执行由 StepExecution 类的对象表示。每次执行都包含对其对应步骤和 JobExecution 的引用,以及与事务相关的数据,例如提交和回滚次数以及开始和结束时间。此外,每个步骤执行还包含一个 ExecutionContext,其中包含开发者需要在批处理运行之间持久化的任何数据,例如用于重启的统计信息或状态信息。下表列出了 StepExecution 的属性:
属性 |
定义 |
|
一个 |
|
表示执行开始时的当前系统时间的 |
|
一个 |
|
|
|
包含需要在执行之间持久化的任何用户数据的“属性包”。 |
|
已成功读取的项目数量。 |
|
已成功写入的项数。 |
|
此执行中已提交的事务数量。 |
|
由 |
|
|
|
|
|
被 |
|
|
执行上下文
ExecutionContext 表示由框架持久化并控制的一组键/值对,为开发人员提供了一个存储作用域限定于 StepExecution 对象或 JobExecution 对象的持久状态的位置。(对于熟悉 Quartz 的用户来说,它非常类似于 JobDataMap。)其最佳使用示例是支持重启。以平面文件输入为例,在处理单独的行时,框架会在提交点定期持久化 ExecutionContext。这样做可以让 ItemReader 在运行期间发生致命错误甚至断电时保存其状态。所需做的只是将当前已读取的行数放入上下文中,如下例所示,其余工作由框架完成:
executionContext.putLong(getKey(LINES_READ_COUNT), reader.getPosition());以 EndOfDay 部分中的 Job 刻板印象示例为例,假设存在一个步骤 loadData,用于将文件加载到数据库中。在首次运行失败后,元数据表将呈现如下示例:
JOB_INST_ID |
JOB_NAME |
1 |
每日终结任务 |
JOB_INST_ID |
TYPE_CD |
KEY_NAME |
DATE_VAL |
1 |
日期 |
schedule.Date |
2017-01-01 |
JOB_EXEC_ID |
JOB_INST_ID |
START_TIME |
END_TIME |
状态 |
1 |
1 |
2017-01-01 21:00 |
2017-01-01 21:30 |
失败 |
STEP_EXEC_ID |
JOB_EXEC_ID |
STEP_NAME |
START_TIME |
END_TIME |
状态 |
1 |
1 |
加载数据 |
2017-01-01 21:00 |
2017-01-01 21:30 |
失败 |
STEP_EXEC_ID |
SHORT_CONTEXT |
1 |
{piece.count=40321} |
在前面的案例中,Step 运行了 30 分钟并处理了 40,321 个“片段”,在此场景中这些片段代表文件中的行。该值由框架在每次提交之前更新,并且可能包含多行,对应于 ExecutionContext 中的条目。要在提交之前收到通知,需要使用各种 StepListener 实现之一(或一个 ItemStream),本指南稍后将对此进行更详细的讨论。与前面的示例一样,假设 Job 将在第二天重新启动。重新启动时,上次运行的 ExecutionContext 中的值将从数据库中重建。当 ItemReader 打开时,它可以检查上下文中是否存储了任何状态,并据此初始化自身,如下例所示:
if (executionContext.containsKey(getKey(LINES_READ_COUNT))) {
log.debug("Initializing for restart. Restart data is: " + executionContext);
long lineCount = executionContext.getLong(getKey(LINES_READ_COUNT));
LineReader reader = getReader();
Object record = "";
while (reader.getPosition() < lineCount && record != null) {
record = readLine();
}
}在这种情况下,上述代码运行后,当前行数为 40,322,让 Step 从中断处重新开始。您也可以使用 ExecutionContext 来统计需要持久化的运行本身相关数据。例如,如果一个平面文件包含跨越多行的待处理订单,则可能有必要记录已处理的订单数量(这与读取的行数截然不同),以便在 Step 结束时发送一封邮件,并在邮件正文中注明已处理的订单总数。该框架负责为开发人员存储此内容,
以便将其正确地限定在单个 JobInstance 范围内。很难确定是否应该使用现有的 ExecutionContext。例如,使用上面的 EndOfDay 示例,当 01-01 运行第二次开始时,框架会识别出这是相同的 JobInstance,并且在单个 Step 的基础上,从数据库中取出 ExecutionContext,并将其(作为 StepExecution 的一部分)交给 Step 本身。相反,对于 01-02 运行,框架识别出它是一个不同的实例,因此必须将一个空的上下文传递给Step。框架会为开发者做出许多此类判断,以确保在正确的时间将状态提供给他们。同样重要的是要注意,在任何给定时间,每个StepExecution恰好存在一个ExecutionContext。ExecutionContext 的客户端需要小心,因为这会创建一个共享的键空间。因此,在放入值时应小心,以确保不会覆盖任何数据。然而,Step 在上下文中完全不存储任何数据,因此无法对框架产生不利影响。
请注意,每个 ExecutionContext 至少对应一个 JobExecution,并且每个 StepExecution 也对应一个。例如,考虑以下代码片段:
ExecutionContext ecStep = stepExecution.getExecutionContext();
ExecutionContext ecJob = jobExecution.getExecutionContext();
//ecStep does not equal ecJob正如注释中所述,ecStep 不等于 ecJob。它们是两个不同的ExecutionContexts。作用于Step的那个在每个提交点保存到Step中,而作用于 Job 的那个则在每次Step执行之间保存。
在 ExecutionContext 中,所有非瞬态条目必须为 Serializable。
执行上下文的正确序列化是步骤和作业重启能力的基础。
如果您使用的键或值不是原生可序列化的,则必须采用定制的序列化方法。若未能序列化执行上下文,可能会危及状态持久化过程,导致失败的作业无法正确恢复。 |
作业仓库
JobRepository 是前面提到的所有构造型(stereotype)的持久化机制。
它为 JobLauncher、Job 和 Step 的实现提供 CRUD 操作。当
Job 首次启动时,会从仓库中获取一个 JobExecution。此外,在
执行过程中,通过将 StepExecution 和 JobExecution 的实现传递给仓库来完成持久化。
-
Java
-
XML
使用 Java 配置时,@EnableBatchProcessing 注解会提供 JobRepository 作为自动配置的组件之一。
Spring Batch XML 命名空间支持使用<job-repository>标签配置JobRepository实例,如下例所示:
<job-repository id="jobRepository"/>任务Starters
JobLauncher 表示一个简单的接口,用于使用给定的一组 JobParameters 启动 Job,如下例所示:
public interface JobLauncher {
public JobExecution run(Job job, JobParameters jobParameters)
throws JobExecutionAlreadyRunningException, JobRestartException,
JobInstanceAlreadyCompleteException, JobParametersInvalidException;
}预计实现将从 JobRepository 获取一个有效的 JobExecution,并执行 Job。
ItemReader
ItemReader 是一个抽象概念,代表一次一项地检索 Step 的输入。当 ItemReader 耗尽其可提供的项时,它会通过返回 null 来指示这一点。您可以在 读取器与写入器 中找到有关 ItemReader 接口及其各种实现的更多详细信息。
项目写入器
ItemWriter 是一个抽象概念,代表 Step 的输出,即每次输出一批或一块数据项。通常,ItemWriter 不知道接下来应该接收什么输入,它只知道当前调用中传入的数据项。您可以在 读取器与写入器 中找到有关 ItemWriter 接口及其各种实现的更多详细信息。
项处理器
ItemProcessor 是一个抽象,代表了对某个项的业务处理。
当 ItemReader 读取一个项,且 ItemWriter 写入一个项时,
ItemProcessor 提供了一个用于转换或应用其他业务处理的接入点。
如果在处理该项的过程中确定该项无效,返回
null 表示不应将该项写出。您可以在
Readers And Writers 中找到有关
ItemProcessor 接口的更多详细信息。
批处理命名空间
许多前面列出的领域概念需要在 Spring 中进行配置。
ApplicationContext。虽然你可以使用上述接口的实现类在标准的 Bean 定义中进行配置,但为了简化配置,专门提供了一个命名空间,如下例所示:
<beans:beans xmlns="http://www.springframework.org/schema/batch"
xmlns:beans="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="
http://www.springframework.org/schema/beans
https://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/batch
https://www.springframework.org/schema/batch/spring-batch.xsd">
<job id="ioSampleJob">
<step id="step1">
<tasklet>
<chunk reader="itemReader" writer="itemWriter" commit-interval="2"/>
</tasklet>
</step>
</job>
</beans:beans>